Agentic AI
Quick answer
Agentic AI plans, acts, and self-corrects across multi-step goals. Full definition, agent loop architecture, failure modes, and a vendor acid test for enterprise teams.
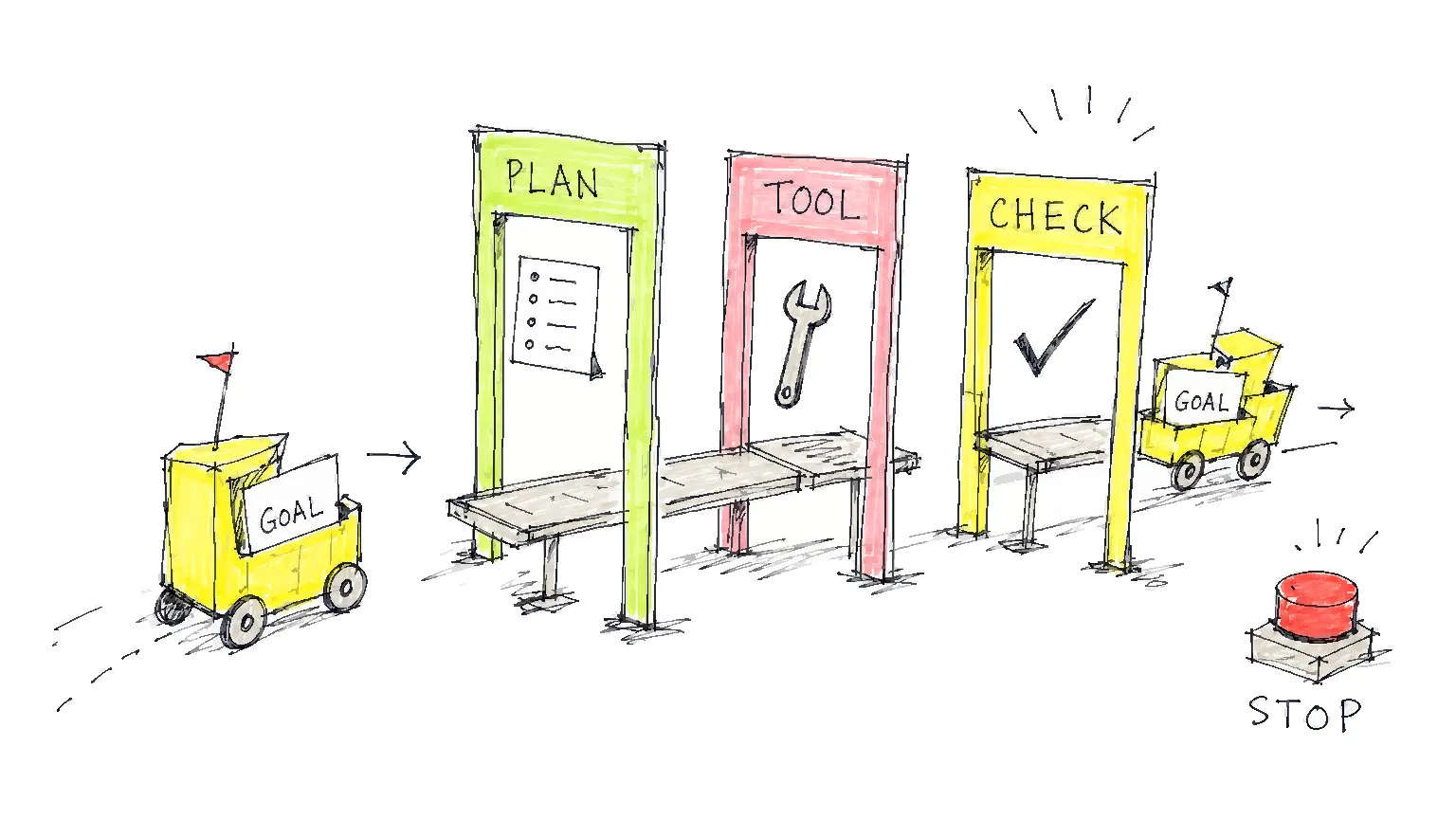
A vendor is calling their product agentic. Here is how to check the claim in under a minute: ask whether the system can critique its own intermediate outputs before proceeding to the next step. If the answer is no, you are evaluating a prompt chain with a rebrand, not an agentic AI system.
Agentic AI is AI that pursues a multi-step goal autonomously, retaining state across steps, calling external tools to act on the world, and evaluating its own progress before deciding what to do next. A system qualifies as agentic when all four properties are co-present: goal persistence, tool-calling, memory, and self-evaluation.1 Remove any one of these and you have capable automation, not an agentic system.
Andrew Ng coined the term to describe “a growing category of AI projects”, though marketers promptly applied it to everything in sight. Gartner (June 2025) now estimates that only about 130 vendors of the thousands claiming agentic capabilities actually deliver them.
TL;DR
- Agentic AI = AI that pursues multi-step goals without waiting for human input at each step, calling tools and revising its approach based on what it observes.
- The four qualifying properties are goal persistence, tool-calling, memory, and self-evaluation. A system missing any one falls outside the definition.
- Autonomy sliders and approval gates do not fix compounding errors. Self-evaluation does.
- Enterprise reality: 35% adoption, 40%+ of projects canceled by 2027, and 80% of implementation effort spent on data engineering.
- The vendor acid test: can the system critique its own intermediate outputs? If not, keep evaluating.
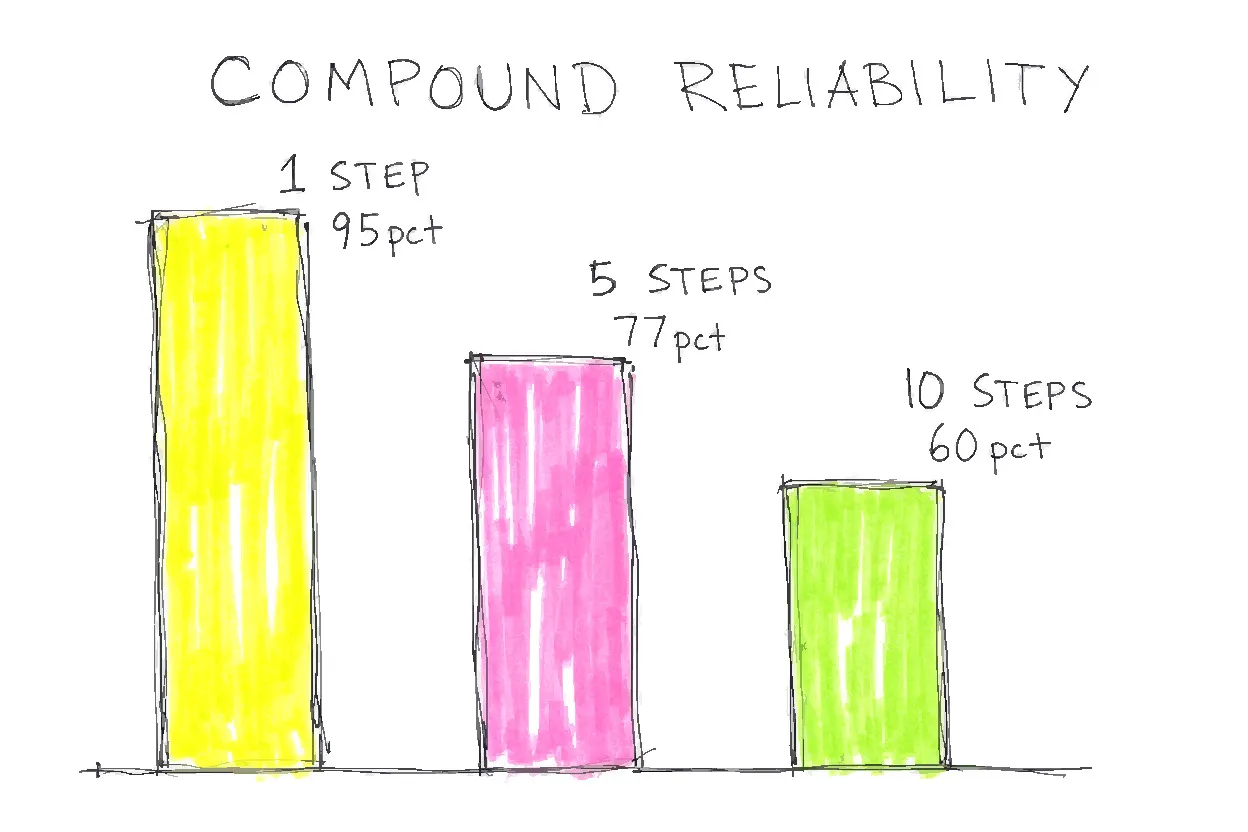
The core tension: agentic AI deployment is accelerating faster than the governance infrastructure required to run it safely, while the fraction of systems that genuinely qualify by the term’s own properties remains a minority of those claiming the label. The compounding math explains the gap: a 95%-per-step-accurate agent achieves only 59% compound reliability across ten steps, and no autonomy control changes that degradation curve — only self-evaluation does.
What is agentic AI?
Agentic AI names a class of AI systems that pursue complex, multi-step goals with little human input required at each step. Memory gives these systems context across a long run. Tools extend their reach into outside services, while self-evaluation catches errors early enough that one mistake does not feed the next. A system is agentic only when all four qualifying properties are active simultaneously.
In a peer-reviewed survey published early 2025, Acharya, Kuppan, and Divya define agentic AI as “autonomous systems designed to pursue complex goals with minimal human intervention”, systems that demonstrate “adaptability, advanced decision-making capabilities and self-sufficiency, enabling it to operate dynamically in evolving environments.” (Acharya et al., IEEE Access 2025) Now among the most-cited definitions in the field (426 citations via OpenAlex as of mid-2026), this framing captures the core properties. A second taxonomy published the same year by Sapkota, Roumeliotis, and Karkee draws a clean line between AI Agents as components and Agentic AI as a system-level property: “a change marked by multi-agent collaboration, dynamic task decomposition, persistent memory, and coordinated autonomy.” (Sapkota et al., Information Fusion 2025)
Goal persistence enables the system to maintain its objective across an indefinite number of steps and tool calls. Without it, the system resets with each prompt — that is a chatbot, not an agentic system.
Tool-calling gives the system real-world effect: writing files, querying APIs, running code, browsing the web. Without it, the system can only generate text.
Memory retains context, prior decisions, and external knowledge beyond the active token window. Without it, context exhaustion on any task exceeding a few steps is inevitable.
Self-evaluation enables the system to critique its own intermediate outputs and revise the plan before proceeding. Without it, errors at step N become inputs at step N+1, compounding across every subsequent step.
The definition matters because the term is actively contested. With at least three competing definitions in active use, a July 2025 arxiv paper surveying AI paradigms for manufacturing concluded that “the definitions, capability boundaries, and practical applications of these emerging AI paradigms in smart manufacturing remain unclear.” (Ren et al., arXiv:2507.01376) A 2025 systematic review across healthcare, finance, and robotics found similar fragmentation, with vendors, frameworks, and academic papers treating the term as interchangeable with “AI agent,” “generative AI workflow,” and “autonomous system.” (Hosseini & Seilani, 2025)
This gets expensive. An innovation manager evaluating a vendor claiming “agentic capabilities” is navigating a term that carries more weight than its words. They are trying to avoid burning a project cycle on a dressed-up workflow. The four-property checklist above is the fastest way to call the claim. Explore related innovation terms to build your complete evaluation vocabulary.
How does the agent loop work?
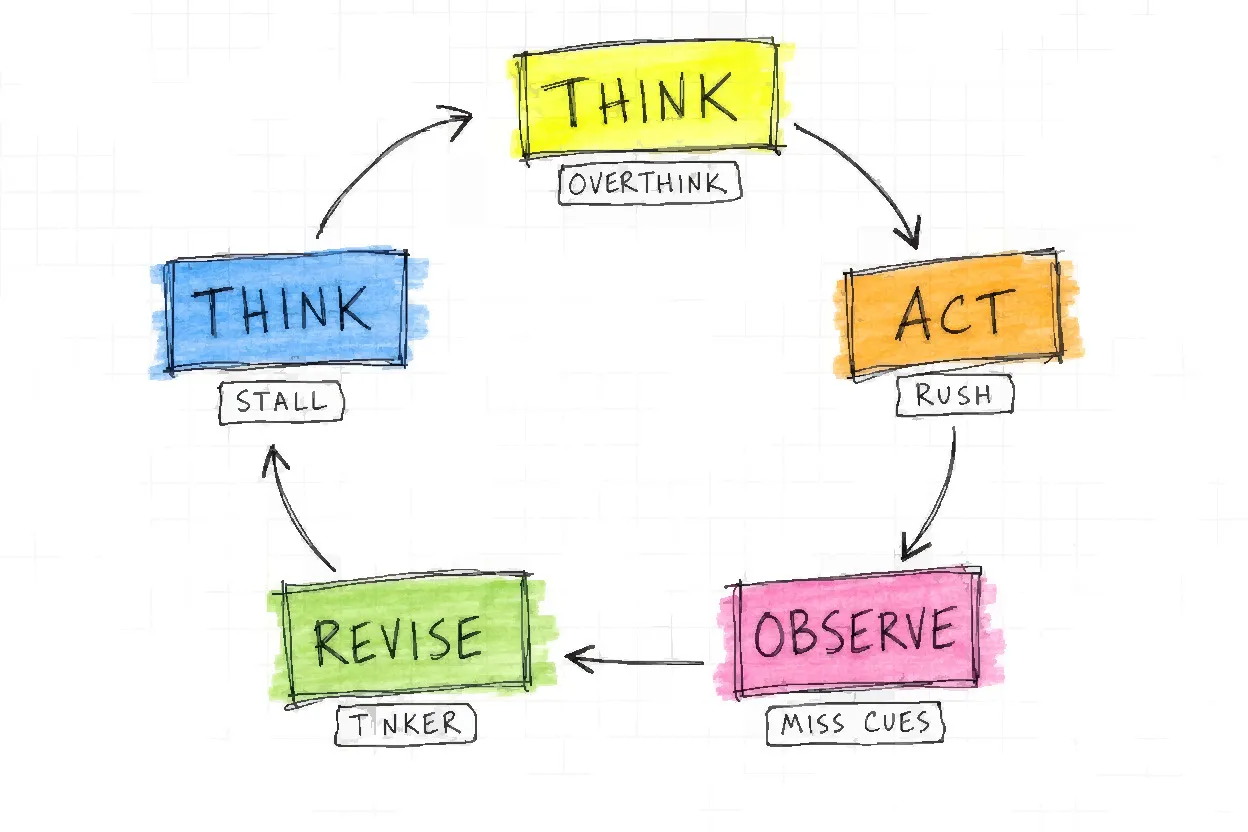
The agent loop is the repeating cycle through which an agentic system pursues its goal. Every iteration follows three canonical steps — Thought, Action, Observation — as formalized by the 2022 ReAct paper (Yao et al.), among the most-cited technical architecture papers in AI (~5,250 citations on Semantic Scholar). The optional fourth step, Reflect or Revise, is what most vendor implementations omit; its absence is the point where systematic errors begin compounding into failures.
The loop is where the label cashes out. Think. Act. Observe. Reconsider. The ReAct paper established the canonical three-step cycle: Thought, Action, Observation, with reasoning traces that “help the model induce, track, and update action plans as well as handle exceptions.” In plain terms: “A language model is the brain. It’s the thing doing the thinking, the reasoning, the processing, all of that. But a brain floating in a jar can’t really do anything. It becomes an agent the moment you give that brain a body, you give it hands and legs and tools that can go and actually do something in the world. A model thinks. an agent thinks and acts.” (Zen Academy, 2026)
The five-step framing common in enterprise vendor documentation (“perceive, plan, act, observe, reflect”) is a community extension of the Yao et al. model, not the original ReAct paper. The reflect or revise step, the one most vendor implementations omit, was added by practitioners after they observed what happened to agents that lacked any self-evaluation mechanism.
Each loop step has a distinct failure mode. At the Thought step, the agent reasons about current state and what to do next; hallucination and incorrect inference are the risks. Self-evaluation detects inconsistency with prior observations. At the Action step, the agent calls a tool with typed arguments; wrong tool selection, bad parameters, and permission errors are the risks. Self-evaluation catches tool errors before committing output. At the Observation step, the agent receives tool output and updates context; stale data, malformed responses, and injected content are the risks. At the Reflect/Revise step, the agent evaluates whether the current plan still leads toward the goal; goal drift is the failure mode, and this step is absent in most implementations.
The distinction between a chatbot and an agentic system is architectural, not a matter of degree. A chatbot calling a search API is not agentic. An agentic system uses the search result to update its plan, decides whether the plan still holds, and either proceeds or revises.
How does agentic AI differ from generative AI and AI chatbots?
The structural difference between a chatbot and an agentic AI system is goal persistence: a chatbot resets state with each prompt; an agentic system maintains the objective across an indefinite number of steps. Memory, tool use, and failure mode all shift as a result.
| Property | Chatbot | AI Agent (component) | Agentic AI (system) |
|---|---|---|---|
| Goal persistence | None — resets each prompt | Within-task only | Across indefinite steps and sessions |
| Tool-calling | Optional / limited | Yes — defined task set | Yes — dynamic, composable |
| Memory | Context window only | Working memory | In-context + external + episodic |
| Self-evaluation | None | None or minimal | Required for loop completion |
| Can revise its own plan? | No | Rarely | Yes — core capability |
| Typical failure mode | Hallucination, off-topic response | Tool error, scope creep | Error compounding across steps |
Generative AI (a broader category covering chatbots, image generation, and code synthesis) describes what a model produces, not how a system is organized. An LLM responding to a prompt is generative AI. The same LLM deciding what tool to call next, observing the result, and revising its plan is operating inside an agentic loop. Same model. Different operating logic.
The distinction between an AI agent (component) and agentic AI (system) causes persistent confusion. Sapkota et al. (2025) separates AI Agents as “modular systems driven by LLMs for task-specific automation” from Agentic AI as a “change marked by multi-agent collaboration, dynamic task decomposition, persistent memory, and coordinated autonomy.” A single agent is a component. Agentic AI describes the system-level property that emerges when those components coordinate.
Cristin Flynn Goodwin, former Head Lawyer at Microsoft Security Response Center and keynote speaker at SecTor 2025, distinguishes agentic from generative AI on three axes: proactivity, multi-source reasoning, and persistence — agentic systems initiate tasks, draw from multiple external data points, and run across time rather than completing in a single turn. Those three properties, combined with self-evaluation, are what make agentic systems meaningfully different, and meaningfully harder to govern.
What separates agentic AI from RPA and workflow automation?
Agentic AI follows a probabilistic plan it can revise mid-execution. That flexibility introduces failure modes absent from RPA. It also opens up capabilities that no rule-based system can match.
Comparing this to an n8n workflow points to a clear distinction. An n8n workflow runs the steps you programmed. An agentic system decides its own steps toward the goal you set. That is the whole distinction: goal-directed vs. step-programmed. It is why agentic systems can handle tasks that would require a human to write a new workflow for every edge case.
The risk profile diverges at the same point. When RPA breaks, the failure is contained and predictable: a script stops because a UI element shifted. The failure is visible, immediate, and fixable by correcting the script. Agentic AI failure is probabilistic and often delayed: an error at step 3 propagates through steps 4, 5, and 6 before any output is visible. Microsoft’s red-team findings confirm this failure mode by name — “goal hijacking” and “session context contamination” are both forms of delayed-propagation error.
RPA wins on predictability and auditability. For regulatory environments requiring a deterministic audit log of every action taken, RPA remains the correct tool. Agentic AI wins on adaptability; tasks that require mid-execution judgment cannot be pre-scripted. The decision frame comes in §14.
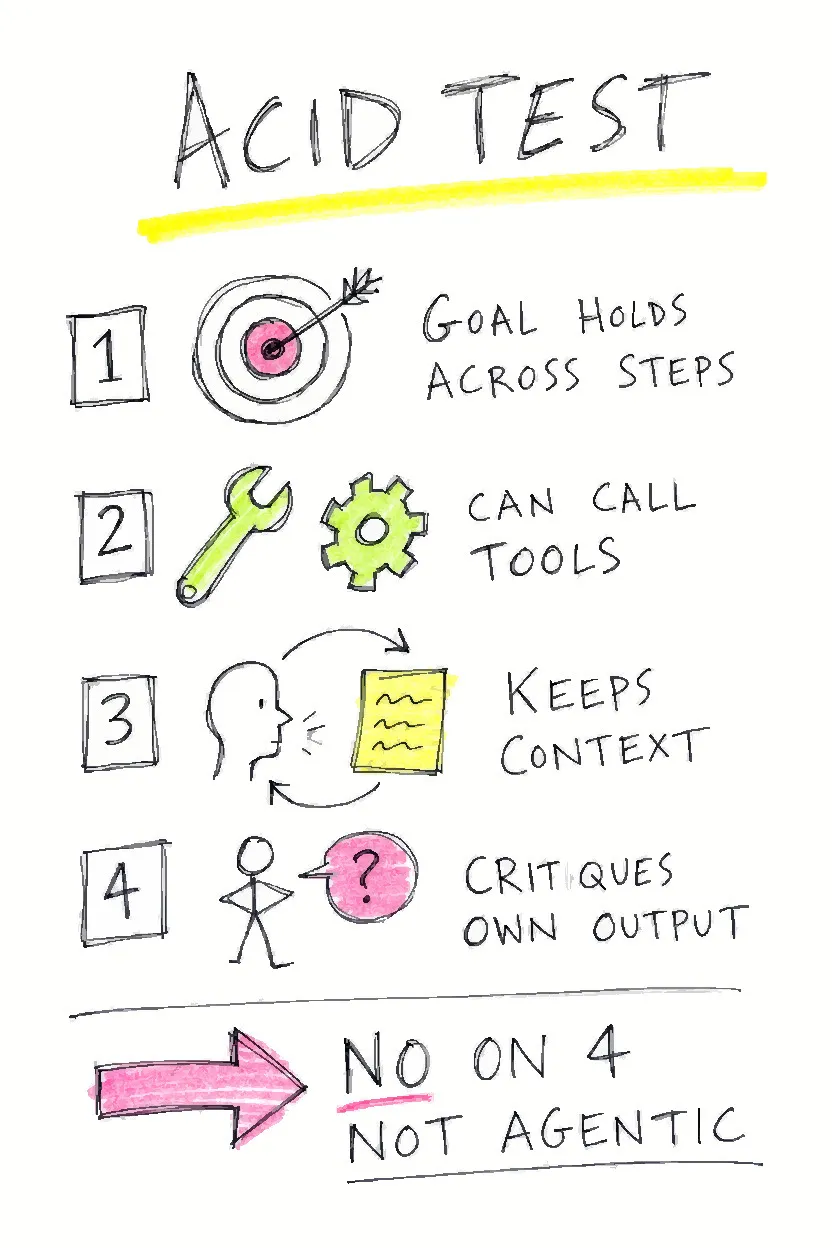
What makes a system genuinely agentic? The self-evaluation acid test
Self-evaluation is the hinge. It is the property that separates systems that course-correct from systems that merely accelerate their own mistakes. The first three qualifying properties cover what an agentic system is built with: goal persistence, tool-calling, and memory. Self-evaluation describes what it does with them. Systems that skip this step do not become more capable versions of what they were. They become systems that compound errors faster.
- Does the system maintain the original goal across steps, or does it require re-prompting?
- Can the system call external tools and act on systems outside its token window?
- Does the system retain context across an entire task, not just the active prompt?
- Can the system detect that its prior output was wrong and revise its plan before proceeding?
If the answer to question 4 is no, the system fails the acid test.
Microsoft’s AI Red Team, after 12 months of adversarial engagements against deployed agentic systems, quantified what happens when self-evaluation is absent:
“Human-in-the-loop bypass was the most consistently exploited failure mode, at very high frequency.” — Microsoft Security Blog, June 2026
The team documented “zero-click end-to-end chains starting from an external input with no human interaction beyond the initial agent invocation.” Self-evaluation is the architectural mechanism that catches these chains before they reach completion. An agent that cannot assess its own outputs cannot identify when it has been redirected.
Enterprise governance focused on autonomy sliders and approval gates is treating the symptom. Compounding errors, session contamination, and HitL bypass all occur independent of how much autonomy an agent has been given, and no approval gate changes that. An approval gate placed between steps 2 and 3 does not catch the goal hijacking that occurred in step 1. It only slows the agent down.
The Princeton research group, publishing in June 2026, measured 18 months of model improvements against reliability metrics and found that “reliability only shows small improvements over time” even as accuracy improves steadily. (Rabanser et al., arXiv:2602.16666) Better models do not automatically fix the compounding failure mode. The architectural fix is the self-evaluation step (which catches errors before step N+1 receives them, breaking the compounding chain) and its absence is the single most reliable predictor of agentic AI pilot failure.
What is “agentic theater,” and how do you spot it?
Agentic theater describes the pattern of applying the term “agentic” to systems that qualify only by the loosest reading — typically prompt chains that call tools but include no reflection or goal-revision step. Gartner calls this “agent washing.” Of the thousands of vendors claiming agentic capabilities, only about 130 actually deliver them. The gap between the claim and the delivery has a precise technical name.
The term coined by the researcher who popularized it, Andrew Ng, DeepLearning.AI’s co-founder:
“I came with the term agentic AI to describe a growing category of AI projects — not realizing that marketers would get a hold of that term and slap a sticker on everything in sight.”
Gartner analyst Anushree Verma put the deployment reality directly in June 2025: “Most agentic AI projects right now are early stage experiments or proof of concepts that are mostly driven by hype and are often misapplied.” The definitional gap is the mechanism. A July 2025 arxiv paper surveying AI paradigms for manufacturing documented it: “the definitions, capability boundaries, and practical applications of these emerging AI paradigms in smart manufacturing remain unclear.” (Ren et al., arXiv:2507.01376) When the bar is contested, any system can clear it.
Three observable patterns that signal agentic theater
Pattern 1: No reflection step in the architecture documentation. Vendor documentation that describes a “plan-execute” cycle without a review or self-assessment step between execution and output is describing a prompt chain. The pattern is common: several major enterprise platform product pages document their “agentic workflows” as goal-decompose-execute sequences, with tool calling but no named reflection or validation step in the cycle. Agentic architecture must include a mechanism by which the agent evaluates its own output before committing.
Pattern 2: Single-turn goal decomposition only. The system takes a goal, breaks it into subtasks at the start, and executes them in order. A genuine agentic system re-evaluates the goal decomposition as it accumulates observations. If the architecture does not support mid-task plan revision, it is a workflow, not an agent.
Pattern 3: No evidence of mid-task plan revision in demos or case studies. Vendor demos that show smooth linear execution without any moment where the agent revises its approach based on an unexpected result are either cherry-picked or not agentic. Ask for a case where the agent’s initial plan failed and describe how it recovered.
How does memory work in agentic systems?
Memory determines how much of a task’s history an agentic system can use when deciding what to do next. Four types operate in production agentic systems, and the absence of any one creates a distinct failure mode.
In-context memory (the active token window) serves the agent’s immediate reasoning chain and recent tool outputs. The failure mode on long tasks is context exhaustion, where older material is silently dropped and the agent loses track of decisions made early in the session. Capacity ranges from roughly 4K to 200K tokens depending on the model.
External retrieval (RAG) gives the agent persistent access to document stores (customer history, product catalogs, knowledge bases) that survive across sessions. The failure mode is the retrieval layer itself: stale embeddings surface outdated information, and any document in the index can carry injected instructions.
Episodic memory logs prior decisions, tool calls, and intermediate results. The failure mode is contamination, which happens because the log records everything regardless of source — adversarial content enters with the same weight as any legitimate observation and, without a validation step, circulates back into active reasoning on the next cycle.
Procedural memory is baked into the model’s weights, domain-specific reasoning patterns that persist across deployments. The failure mode is overfitting to the training distribution — the agent cannot update from new examples at runtime.
Microsoft’s June 2026 red-team taxonomy identifies memory-adjacent failures as a distinct failure class. Session context contamination is structurally a memory problem. Adversarial content injected early persists in the episodic log alongside legitimate observations, shaping later decisions because no self-evaluation step flags the difference.
The practical implication for architecture decisions: an agentic system with in-context memory only is limited to tasks that fit within the model’s context window. An agentic system with external retrieval needs authentication controls on the document index. An agentic system with episodic memory needs validation logic to prevent historic contamination from re-entering active reasoning.
How does tool use and multi-agent coordination work?
Tool-calling is the mechanism by which an agentic system acts on the world outside its token window. Multi-agent coordination extends this by distributed coordination across specialized agents, each focused on a subtask.
Tool-calling
Tools are callable functions with typed arguments. During the Action step, the agent picks one based on its current reasoning, passes whatever arguments the function requires, and receives back an observation that enters the next reasoning cycle. In practice, a tool can be any external interface that accepts typed input and returns structured output.
The design space matters: a poorly scoped tool (one with overly broad permissions or no validation on inputs) is a direct attack surface. The security answer is least privilege: each tool gets only the access the task actually requires, nothing beyond. Microsoft’s June 2026 taxonomy classified “MCP/Plugin Abuse” as an already-active production risk, citing the Asana May 2025 breach: approximately 1,000 customers were affected through cross-tenant data visibility via an agentic integration. Plugin permissions define the agent’s blast radius.
Multi-agent coordination
Scout-and-evaluator is the common pattern. One agent gathers, a second assesses, and an orchestrator routes decisions between them in a loop that distributes work across specialized components and allows tasks to run in parallel. The cost of that architecture is a new class of trust problem that the pattern itself does not resolve.
When Agent A passes output to Agent B, Agent B implicitly trusts that output, unless trust architecture explicitly prevents it. Microsoft’s failure taxonomy identified “Inter-Agent Trust Escalation” as a new category in the June 2026 update: compromising one subagent can propagate privilege across the entire system.
Identity management scales with agent count. Ten agents per employee at a 1,000-person company produces 10,000 non-human identities. Current identity infrastructure was not designed to authenticate, authorize, and monitor that volume on top of all the human identities the organization already manages. (Cristin Flynn Goodwin, SecTor 2025)
Agentic AI by the numbers
Adoption data, forecast data, and production reality data tell different stories about the same technology. Gartner projects 40% of enterprise apps will embed AI agents by end-2026; the CAIS Remote Labor Index shows the best available agent completes 2.5% of real paid tasks successfully. Neither number is wrong — they measure different variables in the same deployment equation. Read all three data categories before making a decision.
| Stat | Source | Year | What it shows |
|---|---|---|---|
| 40% of enterprise apps will embed AI agents by end-2026 | Gartner (Anushree Verma) | Aug 2025 | Growth pace from <5% in 2025 |
| 15% of day-to-day work decisions will be made autonomously by 2028 | Gartner | Jun 2025 | Long-term autonomy trajectory |
| 40%+ of agentic AI projects will be canceled by end-2027 | Gartner | Jun 2025 | Risk of premature deployment |
| $450B forecast agentic AI share of enterprise software revenue by 2035 | Gartner | Aug 2025 | Market scale projection |
| 35% current agentic AI adoption; 44% planning deployment | MIT Sloan/BCG survey (2,102 respondents, 116 countries) | Nov 2025 | Adoption spread |
| 80% of implementation effort on data engineering, governance, integration | MIT Sloan/BCG survey | Nov 2025 | Where the real work lives |
| 853 full-time employee equivalents handled by Klarna’s AI agent | Klarna Q3 2025 earnings call | Nov 2025 | Flagship ROI case |
| $60M in cost savings from Klarna’s AI agent | Klarna Q3 2025 earnings call | Nov 2025 | Financial impact (see nuance below) |
| Only 14% of organizations have agentic solutions ready for deployment | Deloitte Tech Trends 2026 | Dec 2025 | Readiness deficit |
| Only 21% of enterprises have mature governance models for agentic AI | Deloitte (Apr 2026) | Apr 2026 | Governance gap |
| 57% claim AI agents “in production”; 11% have agents at genuine scale | Futurum Group / G2 Aug 2025 survey | Dec 2025 | 46-point definitional gap |
| Best agent (Manus): 2.5% completion on real paid tasks | CAIS Remote Labor Index benchmark | Nov 2025 | Hard performance ceiling |
Trust data belongs alongside the deployment forecasts. Deloitte’s 2026 research found only 14% of organizations have agentic solutions ready for deployment, only 21% have mature governance models, and 74% expect moderate-to-extensive AI agent usage by 2027. The governance gap between adoption pace and infrastructure readiness is the deployment risk in three numbers. Gartner’s Anushree Verma described the forward trajectory in August 2025: “AI agents are evolving rapidly, progressing from basic assistants embedded in enterprise applications today to task-specific agents by 2026 and ultimately multiagent ecosystems by 2029.” Adoption accelerating into a governance deficit is the challenge in a sentence.
The Klarna nuance. Klarna’s figures are real, sourced from the Q3 2025 earnings call, where CEO Sebastian Siemiatkowski confirmed 853 full-time employee equivalents and $60M in savings. But total customer service and operations costs increased year-over-year ($50M in Q3 vs. $42M prior year). AI agent savings and total operational costs moved in opposite directions. Klarna also re-hired some human representatives after initially over-automating. The 853/$60M headline is accurate — it describes one variable in a more complex picture.
The benchmark floor. The Center for AI Safety’s Remote Labor Index tested the best available agents on 240 paid freelance tasks averaging 11.5 hours each — tasks real humans had been paid to complete. The best-performing agent (Manus) completed 2.5% of tasks successfully. GPT-5 completed 1.7%. The other 97.5% failed. These are open-ended real-world tasks, not structured benchmark scenarios. The gap between vendor demos and this baseline is the reliability gap.
The Gartner forecast and the CAIS benchmark are both accurate statements about different things. Gartner is measuring planned adoption rates. CAIS is measuring actual task completion on representative work. Both belong in an enterprise evaluation.
Mini-case: OpenClaw and the anatomy of an agentic security failure
The OpenClaw incident of January 2026 is the most documented agentic AI security failure on record. A self-hosted agent grew to 180,000+ GitHub stars before a critical remote code execution flaw was patched, leaving up to 42,000 instances vulnerable and exposing 341 malicious marketplace skills — three of Microsoft’s seven failure categories in one production system.
What happened
In November 2025, Austrian developer Peter Steinberger released Clawdbot, a self-hosted AI agent capable of automating tasks across messaging platforms (WhatsApp, Telegram, Discord, Slack, Signal, iMessage, Teams), with access to file operations, browser control, and financial transactions. On January 27, 2026, he rebranded it OpenClaw and open-sourced it. Within 24 hours, the project accumulated 9,000 GitHub stars. Within days, 180,000+ stars. (Reco.ai incident analysis)
The vulnerability
Before that viral growth was 48 hours old, security researchers identified CVE-2026-25253: a CVSS 8.8 remote code execution vulnerability in the WebSocket implementation. The flaw was an unvalidated gatewayUrl parameter that accepted values directly from query strings — a one-click remote code execution via WebSocket hijacking. The patch came January 30, 2026.
By then: up to 42,000 instances were publicly accessible and vulnerable, 93.4% of them lacking authentication controls. A separate analysis found 341 malicious skills in the ClawHub marketplace (12% of the total registry) designed to hijack agent behavior in already-deployed instances.
Heather Adkins, Google Cloud VP Security, reduced her recommendation to three words: “Don’t run Clawdbot.”
The anatomy of the failure
Three failure modes from the Microsoft taxonomy map onto the OpenClaw incident:
MCP/Plugin Abuse: The 341 malicious marketplace skills exploited the same trust model that made OpenClaw useful in the first place. Installing a skill granted it access to whatever the agent could reach, including file systems and financial APIs, and no validation mechanism existed to distinguish a legitimate skill from an adversarial one.
Agentic Supply Chain Compromise: An agent’s behavior can be influenced by content embedded in upstream instructions without code injection. The malicious skills embedded adversarial instructions at the source.
Capability/Architecture Disclosure: The tool’s public documentation and marketplace made its full permission surface visible, enabling targeted attack development before any defenses were in place.
What a self-evaluation mechanism would have changed
The missing property was self-evaluation applied to input validation. The agent executed skills without assessing whether the skill’s permission requirements were consistent with the user’s stated goal. A self-evaluation step checking “does this skill request access I would not grant to an external tool I had not vetted?” would not catch every attack, but it would have caught the most obvious category: skills requesting elevated permissions for tasks that do not require them.
OpenClaw’s creator, Peter Steinberger, joined OpenAI in February 2026. The OpenClaw Foundation assumed governance of the project.
What are the failure modes of agentic AI, and why do errors compound?
In a sequential multi-step system, errors accumulate differently than in a single-turn system. Each step takes the prior step’s output as input. An error at step N conditions step N+1 toward further error, not independently, but correlated. This is not a theoretical concern. Princeton researchers studying 18 months of model improvements found that “reliability only shows small improvements over time” even as accuracy metrics improve steadily. The optimistic model (“better models will fix this”) is empirically false by their measurement.
The compounding math. An agent with 95% step-level accuracy across 10 sequential steps achieves compound system reliability of 0.95^10 = 0.599, or roughly 60%. Fifteen steps drops that to 46%. This calculation assumes independent errors — the optimistic case. Rabanser et al. (Princeton, 2026) show real-world errors are correlated, not independent: errors in step N actively condition the context toward additional error in step N+1. The actual degradation curve is steeper. Self-evaluation is the only architectural mechanism that breaks this chain, catching errors before they propagate as inputs to the next step.
The Microsoft taxonomy. After 12 months of adversarial red-team engagements against deployed agentic systems, Microsoft’s AI Red Team (June 2026) published an updated taxonomy identifying seven new failure categories: Agentic Supply Chain Compromise (adversarial content in upstream agents, prompts, or retrieved documents, no code injection required). Goal Hijacking (subtle terminal goal redirection that bypasses detection, goals shift incrementally, not all at once). Inter-Agent Trust Escalation (compromising one subagent to propagate privilege across the system). Computer Use Agent Visual Attack (screen-based manipulation via visual inputs, images are as attackable as text). Session Context Contamination (incremental injection across session steps that looks normal step-by-step, detectable only via full-session behavioral analysis). MCP/Plugin Abuse (already an active production risk via malicious skills and integrations). and Capability/Architecture Disclosure (eliciting system internals to enable targeted attacks, the precursor category that enables the others). The same report also points to XPIA (cross-prompt injection attacks that move hostile instructions across prompts, tools, or retrieved context) as a reliable initial-access pattern in agentic systems.
The report identified HitL bypass as “the most consistently exploited failure mode, at very high frequency,” achieved through consent fatigue, probabilistic invocation manipulation, and incremental escalation chains.
Microsoft’s principal AI security researcher Pete Bryan, presenting at BlueHat 2026, named the structural vulnerability directly:
“You don’t need to break a model in an agentic system. You just need to exploit everything around it. Jailbreaks aren’t the kind of big focus anymore with agentics. It’s those multiple stepping stones exploiting small parts of the architecture to get you where you need.”
Named real-world failures. On November 13, 2025, Anthropic disclosed what it describes as the first documented AI-orchestrated cyberattack at scale:
“We believe this is the first documented case of a large-scale cyberattack executed without substantial human intervention.”
A Chinese state-sponsored group used Claude to conduct 80–90% of a multi-phase cyberattack autonomously across roughly 30 global targets, requiring human intervention only at 4–6 critical decision points per operation. The attack succeeded because the agent was given a decomposed task that looked innocent in isolation — the self-evaluation gap that the Microsoft taxonomy classifies as Goal Hijacking.
What are the most common misconceptions about agentic AI?
A July 2025 arxiv survey noted that terminology confusion is not incidental, it is systematic, with “definitions, capability boundaries, and practical applications” disputed across papers, vendors, and frameworks. (Ren et al., arXiv:2507.01376) The misconceptions below map directly to the four qualifying properties.
Misconception 1: “Agentic AI is just a capable chatbot”
Why it persists: Both use LLMs. Both produce text responses. The surface resemblance is real.
What the evidence shows: The structural difference is goal persistence. A chatbot resets state with each prompt. An agentic system maintains the objective across dozens or hundreds of tool calls. Pete Bryan from Microsoft’s AI Red Team: “A chatbot with a tool that can reach a point is not an agent, despite what marketing will sometimes tell you.” The defining criterion is not capability level, it is whether the system maintains a goal across steps independently.
Misconception 2: “More autonomy makes agentic AI better”
Why it persists: The term “agentic” implies autonomous action. The intuitive conclusion is that more autonomy means more capability.
What the evidence shows: Autonomy controls the permission surface, not the failure rate. An agent with 95% step-level accuracy fails 40% of 10-step tasks regardless of whether it has been given 20% or 80% autonomy. Andrej Karpathy, in October 2025, put the problem directly: “They don’t have continual learning. You can’t just tell them something and they’ll remember it. They’re cognitively lacking, and it’s just not working.” He reversed this assessment in January 2026 (concluding agents had crossed “some kind of threshold of coherence”) but the structural critique of reliability stands regardless of the capability trajectory.
Misconception 3: “The model quality is the primary variable in agentic system performance”
Why it persists: Enterprise AI purchasing often focuses on model benchmarks (MMLU, HumanEval, etc.) as the quality signal.
What the evidence shows: The MIT Sloan/BCG survey of 2,102 respondents across 116 countries found that:
“80% of the work was consumed by unglamourous tasks associated with data engineering, stakeholder alignment, governance, and workflow integration.”
Model selection is not the primary implementation challenge. Infrastructure decisions, not model quality, determine whether a production deployment succeeds, with the data pipeline, retrieval index, tool permission architecture, and self-evaluation mechanism each capable of causing failure independently. Swapping a better model into a poorly-architected pipeline produces marginal improvement.
Misconception 4: “Governance = approval gates between steps”
Why it persists: Adding human checkpoints at key decision points feels like the natural governance response.
What the evidence shows: Approval gates reduce the blast radius of errors that reach them. They do not address session contamination that occurred before the checkpoint, goal hijacking that redirected the agent subtly enough to pass human review, or supply chain compromise that entered the system through a retrieved document. Deloitte’s April 2026 governance report found only 21% of enterprises have mature governance models for agentic AI, and its recommendation is not more approval gates but a full silicon workforce governance model: digital identity, cryptographic receipts, immutable action logs, and lifecycle management.
Misconception 5: “Agentic AI failure is obvious when it happens”
Why it persists: Traditional software failures produce immediate error messages. Teams assume AI failures will be similarly visible.
What the evidence shows: Individual steps looked normal. Microsoft’s red-team findings showed that detecting session context contamination required “behavioral analysis across the full session” because nothing in a single step stood out as anomalous. The Replit AI assistant incident (July 2025) and OpenAI Operator’s unauthorized purchase both completed before any alert triggered. That pattern is the argument for behavioral monitoring across complete sessions rather than per-step logging.
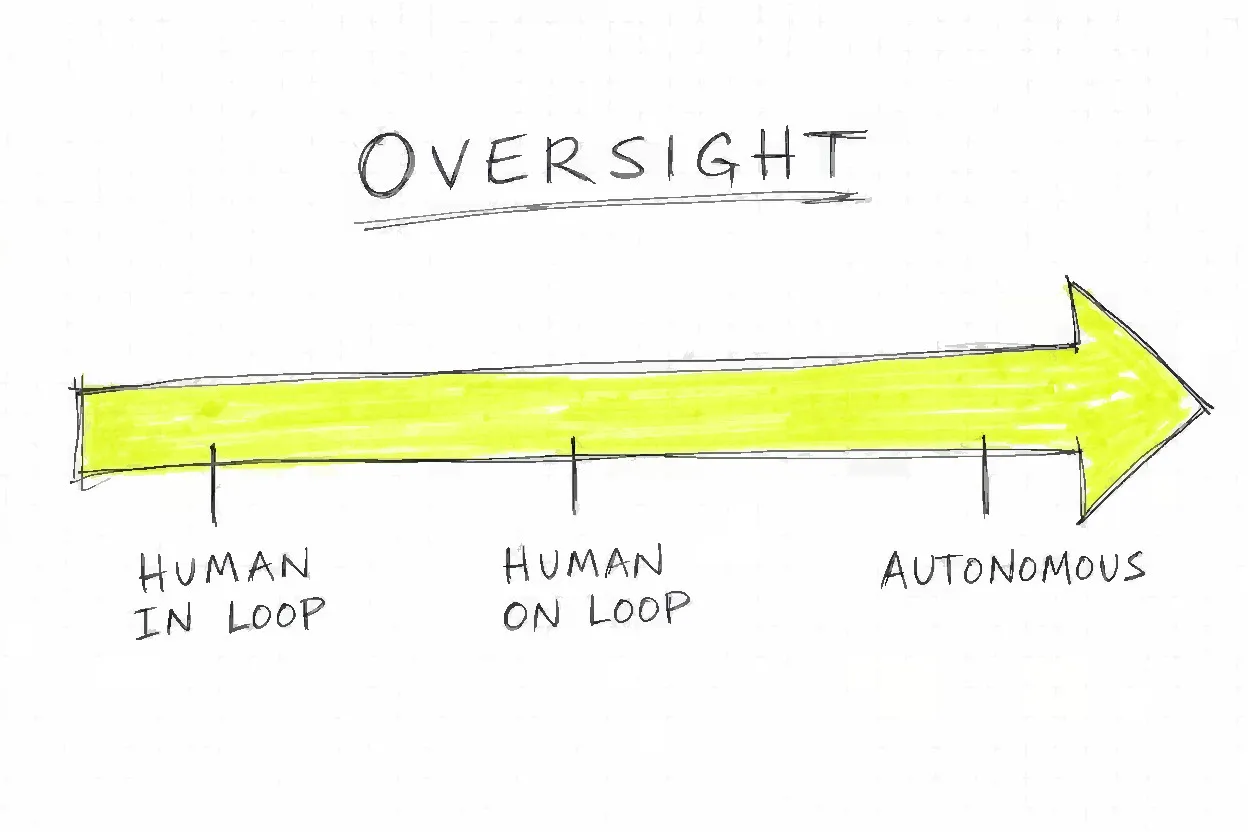
Where are the edge cases? When is “agentic enough” good enough?
Human oversight of agentic systems exists on a spectrum. The useful frame is a spectrum from human-in-the-loop (approval required at every decision point) to human-on-the-loop (alerts only, post-hoc review) to fully autonomous (no human intervention).
The oversight spectrum
The AURA framework (Agent Autonomy Risk Assessment, arXiv:2510.15739, University of Exeter) classifies deployed agents into two operational modes and three enterprise deployment tiers:
- Synchronous (human-supervised): the agent pauses and solicits human feedback at uncertainty thresholds. Higher latency; lower compounding risk.
- Asynchronous (autonomous): the agent runs independently, logging actions for post-hoc review. Lower latency; full compounding exposure.
Human-in-the-loop gates do reduce error rates in bounded contexts. Mitchell et al. (2025) report one organization cut critical errors from 23% to 5.1% after implementing structured checkpoints. That result reflects task scoping and a shorter task horizon, not a fix to how agents reason within a session. Contamination that already entered the context before the first checkpoint was placed is untouched by any gate that comes after.
A separate risk runs in the other direction. BCG and HBR researchers published empirical findings in May 2026 that anthropomorphizing agents (listing them on org charts, assigning them names) reduced individual accountability and increased blame-shifting to the technology. Structured oversight works; treating agents like colleagues produces behavioral problems in the humans doing the overseeing.
For constrained, low-stakes, well-defined tasks (document summarization, structured data extraction, status report generation) human-on-the-loop governance is defensible. The error stakes are low and recoverable. For multi-step tasks with financial, legal, or security implications, the synchronous mode is required until the system has demonstrated reliability across enough similar tasks to establish a track record.
The 80/20 implementation reality
First-time evaluators of agentic AI almost always misjudge where the real effort lands. MIT Sloan and BCG’s survey of 2,102 respondents found 80% of implementation effort consumed by data engineering, stakeholder alignment, governance, and workflow integration, not model selection. A team that has chosen an LLM before designing its data architecture is starting from the wrong end. Build a governance roadmap before you select a model.
When “agentic enough” is sufficient
For low-stakes bounded work, a system with goal persistence and tool-calling but no formal self-evaluation step is often the smarter buy, provided a human reviews the output before it can do damage. This is not an agentic system by the four-property definition. It is a capable workflow with agentic properties. Within that narrow lane, it is the right architectural choice.
The governance difference between “agentic” and “agentic enough”: the former requires behavioral monitoring across full sessions; the latter can be governed with per-step logging. If the task fits within logging-based governance, default to the simpler architecture. Anything heavier is buying complexity before buying reliability.
When should you use agentic AI — and when shouldn’t you?
Agentic AI is the right tool for multi-step, goal-directed tasks that exceed either the cognitive capacity or throughput capacity of human teams or deterministic automation — tasks where adaptability is the constraint, not auditability.
It is the wrong tool for tasks that require certified auditability at each step, where failure is irreversible and fast, or where the goal is so ambiguous that no decomposition strategy holds.
The five-question decision checklist
- Is the task multi-step and goal-directed? If a human would need to make 10 or more decisions to complete it, deterministic automation cannot do it without a new script for each edge case.
- Is the task data-rich with defined success criteria? Agentic systems fail on ambiguous goals and sparse data. If you cannot define what “done” looks like, the agent cannot evaluate its own progress.
- Is failure in this task recoverable? If one error cascades to irreversible consequence (financial transaction, medical decision, legal document filing), full autonomous execution is not appropriate before a reliability track record exists.
- Does the volume justify the implementation cost? The 80% data engineering cost applies whether the task runs once or 10,000 times. High-volume, repetitive tasks amortize that cost; one-off tasks do not. (MIT Sloan/BCG survey)
- Is speed a constraint that prohibits human-on-the-loop review? If the task happens faster than a human can review outputs, the oversight model must be built into the architecture, not added as a downstream review step.
Invoice processing and document classification are the clear cases for RPA or workflow automation: deterministic by design and cheaper to implement than agentic alternatives at this task type. Research synthesis and customer support routing fit agentic AI with synchronous oversight because edge cases arise constantly and re-scripting every variant is not feasible. Financial compliance and legal review require human-in-the-loop approval at each key decision, given that irreversibility prohibits full delegation. Single-turn tasks like Q&A don’t need agentic overhead. Ambiguous goals and low-quality data belong with a human team, since no agent can decompose a goal it cannot define.
Deloitte’s “silicon workforce” governance model argues for treating agents as a workforce category requiring HR-like lifecycle management: onboarding, performance monitoring, retraining, and offboarding with immutable action logs. The practical synthesis: treat vendor evaluation rigorously before deployment — defined roles, limited permissions, logged actions, and a named human accountable for each agent’s scope.
Frequently asked questions
Is ChatGPT agentic AI?
Standard ChatGPT is not agentic. It resets goal state with each conversation and does not maintain a persistent objective across sessions. ChatGPT with operator tasks enabled (where it can hold a goal across a session and call tools) approaches the definition but typically lacks a formal self-evaluation step. GPT-5’s agentic mode, if it includes a reflection mechanism, would qualify. The test is not the model — it is whether all four properties are active simultaneously. (Pete Bryan, Microsoft AI Red Team)
What are the main failure modes of agentic AI in production?
The seven new failure categories identified by Microsoft’s AI Red Team after 12 months of adversarial testing (June 2026) are: Agentic Supply Chain Compromise, Goal Hijacking, Inter-Agent Trust Escalation, Computer Use Agent Visual Attack, Session Context Contamination, MCP/Plugin Abuse, and Capability/Architecture Disclosure. Human-in-the-loop bypass was identified as the most consistently exploited failure mode. Compounding errors (where step-level accuracy degrades multiplicatively over a multi-step task) and context contamination are structural failure modes independent of any taxonomy. (Princeton, arXiv:2602.16666)
When should a team use agentic AI versus a simpler workflow tool?
Use agentic AI when the task is multi-step, goal-directed, data-rich, and high-volume enough to amortize the 80% data engineering implementation cost, and when edge-case handling that cannot be pre-scripted is required. Use a simpler workflow tool when the task sequence is fixed, the audit requirement is deterministic, or failure is fast and irreversible. The 5-question checklist above is the practical decision frame. (MIT Sloan/BCG, 2025)
What does human-in-the-loop mean for agentic AI, and how much oversight is needed?
Human-in-the-loop means the agent pauses and requests human approval at defined decision points before proceeding. Human-on-the-loop means the agent acts autonomously and alerts a human to review outputs after the fact. The right level hinges on task stakes and horizon, with error recoverability as the deciding factor. The AURA framework provides a formal method for quantifying which oversight mode is appropriate using gamma-based risk scoring. Adding human checkpoints reduces error rates in bounded contexts, but checkpoints do not address failure modes like session contamination that occur between them. (Mitchell et al., 2025)
How do I evaluate a vendor’s agentic AI claims before signing a contract?
Apply the four-question acid test: Does the system maintain goals across steps? Can it call external tools? Does it retain memory? Can it critique its own intermediate outputs? If the vendor’s documentation does not describe the self-evaluation step, ask for a demo where the agent’s initial plan fails and show how it recovers. Ask for a production case study with error rate data, not just a success metric. Gartner estimates only about 130 vendors of the thousands claiming agentic capabilities actually deliver them — the vendor evaluation burden is real. (WION/Gartner podcast)

Footnotes
-
Acharya et al., IEEE Access (2025) — “autonomous systems designed to pursue complex goals with minimal human intervention” ↩

Clara @cla_reinholt
Focuses on innovation communication, facilitation, and turning frameworks into team habits.